이상현
in
유럽
자바 바이트코드 소개
Understanding bytecode and what bytecode is likely to be generated by a Java compiler helps the Java programmer in the same way that knowledge of assembly helps the C or C++ programmer. - IBM developerWorks journal
개발을 하다 보면 때로는 로우 레벨에 대한 이해가 필요할 때가 있습니다. 하지만 이클립스나 인텔리J와 같은 IDE를 이용해 개발하는 개발자들에게는 javac나 javap와 같은 간단한 자바 명령어조차 낯선 것이 사실입니다.
이 글에서는 자바 바이트코드(Bytecode)에 대해 살펴보며 자바 프로그램이 어떤 식으로 컴파일되고 실행되는지에 대해 설명하겠습니다.
컴파일러
자바 바이트코드는 JVM(Java virtual machine)이 실행하는 명령어 집합입니다. 컴파일하면 생성되는 .class 파일이 바이트코드를 담고 있습니다.
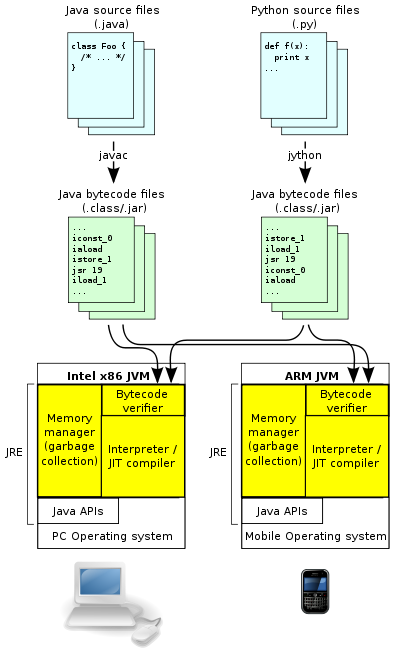
위 그림과 같이 컴파일을 통해 생성된 바이트코드 파일들은 OS나 개발환경에 관계없이 같은 명령어 집합을 사용하며, 이것이 자바의 크로스 플랫폼 동작을 가능하게 해주는 부분입니다.
위 JVM 아키텍처를 자세히 보면 (우측의 Python 관련 그림을 제외하고 보더라도) 두 종류의 컴파일러가 있다는 것을 알 수 있습니다. 첫 번째 컴파일러는 자바 코드를 자바 클래스 파일로 만들어주는 컴파일러입니다. 위 그림에서는 javac로 표기된 부분으로 JDK(Java Development Kit)에 포함된 기본 컴파일러입니다. 일반적으로 자바 컴파일러를 말할 때에는 바이트코드를 생성하는 이 컴파일러를 말합니다. 이후에 JRE(Java Runtime Environment)에서 더 나은 최적화를 하기 위해서 이 단계에서는 loop unrolling, algebraic simplification, strength reduction와 같은 기본적인 최적화도 하지 않습니다.
참고로 이클립스는 독자적인 컴파일러를 사용합니다. 따라서 JDK를 설치하지 않고도 이클립스에서 컴파일이 가능합니다. 이클립스의 컴파일러는 다음과 같은 기능을 제공합니다.
- 프로젝트에서 수정된 부분만 컴파일하는 증분컴파일(Incremental compilation) 기능
- 일부 코드에 에러가 있더라도 클래스 파일을 생성하는 기능(모든 파일이 정상 컴파일되지 않더라도 프로젝트가 동작할 수 있도록 하기 위함)
- AST 생성(Outline 보기, 리팩토링과 같은 기능을 가능하게 함)
위 아키텍처에서 다음으로 볼 수 있는 컴파일러는 JIT(Just In Time) 컴파일러입니다. JVM은 동적으로 바이트코드를 읽으며 인터프리팅을 하는데, 이 단계에서 JIT 컴파일러는 자바 애플리케이션의 성능향상을 위해 동적 컴파일을 통해 머신코드(Machine code)로 컴파일 가능한 코드들을 한 번 더 컴파일합니다. 이처럼 미리 컴파일하지 않고 실행 중 동적으로 컴파일하는데, 컴파일러의 이름이 Just In Time인 이유가 바로 여기에 있습니다.
바이트코드는 공부할 가치가 있을까?
바이트코드 학습을 통해 얻을 수 있는 것에는 어떤 것들이 있을까요? 바이트코드를 분석할 수 있게 되어 좀 더 성능이 좋은 코드를 작성할 수 있을까요? 별로 그렇지 않습니다. 앞서 이야기했듯이 성능 최적화는 JIT 컴파일러 단계에서 진행되며 이것은 JVM마다 다르게 구현되어 있어 사실상 바이트코드만으로는 해당 코드가 어떻게 머신코드로 변경되고 최적화될지 알 수 없습니다. 바이트코드 수준의 최적화란 거의 의미가 없다고 볼 수 있으며, 그것보다 중요한 것은 사람이 보기 좋은 코드를 작성하는 것입니다.
그렇다면 바이트코드는 왜 배워야 할까요. 어셈블리어를 왜 배워야하냐는 질문에 대한 답변으로 나온 아래 문장이 바이트코드를 배워야 하는 이유를 잘 설명해줍니다.
Because you'll understand how it really works.
조금 더 덧붙이자면 바이트코드에 대한 이해는 더 훌륭한 자바 개발자가 되도록 도와줄 것이라는 점입니다.
바이트코드 명령어(opcode)
한 바이트에는 256개의 값이 있듯이 바이트코드에는 256개가량의 opcode들이 존재합니다. 각각의 명령어들은 넓게 다음과 같이 분류할 수 있습니다.
- 읽고 쓰기 (e.g. aload_0, istore)
- 산술논리 연산 (e.g. ladd, fcmpl)
- 타입변환 (e.g. i2b, d2i)
- 객체생성 및 조작 (new, putfield)
- 오퍼랜드 스택 관리 (e.g. swap, dup2)
- 제어 (e.g. ifeq, goto)
- 함수 호출 및 반환 (e.g. invokespecial, areturn)
많은 명령어는 피연산자(operand)의 타입을 나타내는 접두사(prefix) 또는 접미사(suffix)를 가지고 있습니다. 아래는 각 접두사/접미사가 나타내는 피연산자 타입입니다.
| 접두사/접미사 | 피연산자 타입 |
|---|---|
i | integer |
l | long |
s | short |
b | byte |
c | character |
f | float |
d | double |
a | reference |
모든 명령어의 리스트는 위키피디아의 Java bytecode instruction listings 페이지에서 찾아볼 수 있습니다.
바이트코드 시작하기
코드를 컴파일하여 바이트코드를 직접 살펴보겠습니다. 바이트코드는 다음과 같은 형식을 가집니다.
<index><opcode> [<operand1> [<operand2>...]] [<comment>]
형식만 봐서는 와닿지 않으니 예제를 통해 살펴보겠습니다.
위와 같은 클래스를 컴파일해보겠습니다.
javac Person.java컴파일되어 나온 Person.class 파일을 통해 바이트코드를 확인해보겠습니다.
javap -c Person위와 같이 기본 자바 클래스 파일 Disassembler 프로그램인 javap를 실행시키면 다음과 같은 코드가 나타납니다.
Compiled from "Person.java" public class Person extends java.lang.Object{ int age;public Person(); Code: 0: aload_0 1: invokespecial #1; //Method java/lang/Object."":()V 4: aload_0 5: bipush 10 7: putfield #2; //Field age:I 10: return
public int getAge(); Code: 0: aload_0 1: getfield #2; //Field age:I 4: ireturn
public void setAge(int); Code: 0: aload_0 1: iload_1 2: putfield #2; //Field age:I 5: return
}
위 바이트코드 중 일부를 살펴보겠습니다.
5: bipush 10위 코드는 인덱스 5에서 bipush라는 opcode가 10이라는 피연산자를 가지고 있습니다. 한 줄 더 살펴보겠습니다.
7: putfield #2; //Field age:I위 코드는 해시(#)가 달린 피연산자를 가지고 있습니다. 이것은 상수풀(constant pool)에서의 인덱스를 나타냅니다. 그리고 해당 피연산자가 가리키는 아이템을 나타내는 주석이 뒤따라 옵니다. 해당 주석은 javap가 생성한 주석입니다.
이제 다시 바이트코드의 형식을 보면 이해가 잘 될 것입니다.
<index><opcode> [<operand1> [<operand2>...]] [<comment>]
이번에는 Person 클래스의 바이트코드를 부분별로 나누어 분석해보겠습니다.
public Person(); Code: 0: aload_0 1: invokespecial #1; //Method java/lang/Object."":()V 4: aload_0 5: bipush 10 7: putfield #2; //Field age:I 10: return 위 코드는 Person 클래스의 생성자를 나타내는 부분입니다. 코드에는 생성자가 없지만, 컴파일러가 기본 생성자를 만들어냈습니다.
생성자의 첫 줄에서는 aload_0 명령어를 통해 지역변수배열(Array of local variables)의 0번째에 있는 값을 피연산자 스택(Operand Stack)으로 로드합니다.
이것이 대체 무슨 말인지 이해하기 위해 잠시 JVM이 바이트코드를 어떤 방식으로 실행하는지에 대해 살펴볼 필요가 있습니다. JVM은 스택기반머신입니다. 각 스레드는 JVM 스택을 가지고 이 스택에는 프레임(frame)들이 저장됩니다. 프레임은 생성자 또는 함수가 실행될 때 생성되는 것으로 아래 그림과 같이 지역변수배열과 피연산자 스택 그리고 상수풀에 대한 참조로 구성되어 있습니다.

그림의 상단에서 볼 수 있는 지역변수배열에는 객체에 대한 참조(this), 메소드의 인자 그리고 지역변수들이 0번 위치부터 차례대로 들어갑니다. static 함수의 경우에는 파라미터가 0번 위치부터 들어갑니다(static 함수에서는 this를 쓸 수 없습니다).
이클립스를 통해 자바 프로그램을 디버깅해본 경험이 있다면 프레임을 알든 모르든 누구나 프레임을 본 적이 있을 것입니다.

자, 이제 다시 Person 클래스의 바이트코드로 돌아가 보겠습니다(코드가 너무 멀어졌으니 다시 복사해서 보겠습니다).
public Person(); Code: 0: aload_0 1: invokespecial #1; //Method java/lang/Object."":()V 4: aload_0 5: bipush 10 7: putfield #2; //Field age:I 10: return 이제 aload_0이 무엇을 하는지 알 수 있게 되었습니다. 지역변수배열의 0번째 위치에 있던 this를 피연산자 스택에 넣는 동작을 합니다. 앞서 이야기했듯이 aload_0에서 a는 피연산자의 타입을 나타내는 접두사로 참조를 로드한다는 것을 나타냅니다.
다음 라인의 invokespecial 명령어는 상위 클래스(Superclass)의 생성자를 호출합니다. 자바에서 명시적으로 상속을 받지 않는 클래스는 암시적으로 Object를 상속받기 때문에 컴파일러가 이러한 코드를 생성한 것입니다. 이 단계에서 피연산자 스택의 가장 상위에 있던 this가 빠져나오게 됩니다.
다음 인덱스 4~7의 코드들은 age 필드에 10을 할당하는 부분입니다. aload_0을 통해 this를 로드(피연산자 스택에 push)하고 bipush 10을 통해 10을 다시 스택에 넣습니다. 그리고 putfield 명령어에서는 이 두 값과 필드 참조 값 #2를 이용하여 age 필드에 값을 할당합니다.
마지막으로 return 명령어를 통해 반환 값 없이 함수를 종료합니다. 함수가 반환 값을 가질 때에는 areturn 또는 ireturn과 같이 타입 접두사가 붙은 명령어를 실행합니다.
이제 나머지 코드를 살펴보겠습니다.
public int getAge(); Code: 0: aload_0 1: getfield #2; //Field age:I 4: ireturnpublic void setAge(int); Code: 0: aload_0 1: iload_1 2: putfield #2; //Field age:I 5: return
생성자를 보고나니 getter/setter는 쉬워 보입니다.
getAge 메소드에서는 참조를 로드한 후 getfield 명령어에서 참조를 이용하여 age의 값을 다시 스택에 넣습니다. 그리고 ireturn 명령어를 통해 스택의 값을 반환합니다.
setAge 메소드의 명령어들은 생성자에서 사용된 명령어와 같아 다시 볼 필요가 없어보입니다.
if 문과 switch 문 비교
얼마 전 직장동료와 "if 문과 switch 문에 성능차이가 있을까?"라는 것에 관해 이야기 나눈 적이 있습니다. if 문과 switch 문의 성능차이를 이용하여 최적화를 하려고 하는 것은 분명 어리석은 생각이지만 내부적으로 if 문과 switch 문이 어떻게 동작하는지에 대해 알아보는 것은 의미가 있습니다.
같은 동작을 하는 if 문과 switch 문 함수를 준비하였습니다. 각 함수는 static으로 선언하였습니다.
위 클래스의 바이트코드를 확인해보겠습니다.
public static void ifFunc(int); Code: 0: iload_0 1: iconst_1 2: if_icmpne 15 5: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream; 8: iconst_1 9: invokevirtual #3; //Method java/io/PrintStream.println:(I)V 12: goto 27 15: iload_0 16: iconst_2 17: if_icmpne 27 20: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream; 23: iconst_2 24: invokevirtual #3; //Method java/io/PrintStream.println:(I)V 27: returnpublic static void switchFunc(int); Code: 0: iload_0 1: lookupswitch{ //2 1: 28; 2: 38; default: 45 } 28: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream; 31: iconst_1 32: invokevirtual #3; //Method java/io/PrintStream.println:(I)V 35: goto 45 38: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream; 41: iconst_2 42: invokevirtual #3; //Method java/io/PrintStream.println:(I)V 45: return
switch 문의 코드가 조금 더 간결해 보입니다. 바이트코드를 살펴보면 if 문은 if_icmpne 명령어를 통해 한 단계씩 비교하며 이동하는 반면 switch 문은 lookupswitch라는 명령어를 통해 한 번에 목표지점으로 이동하는 것을 알 수 있습니다. switch문이 조금 더 효율적으로 동작할 것이라 예상할 수 있습니다.
바이트코드를 좀 더 자세히 살펴보면 if 문의 인덱스 0에서 iload_0을 통해 로컬변수 배열의 0번째 값을 로드하고 있습니다. 인스턴스 메소드일 경우 0번째 값은 객체참조이지만 여기서 사용된 것은 static 메소드이므로 0번째 값은 첫 번째 인자가 됩니다.
다음 줄에서는 iconst_1 명령어를 통해 int 값 1을 스택에 넣습니다. 기억력이 좋은 분이라면 앞서 Person 클래스에서는 10이라는 값을 age 필드에 할당할 때 bipush 명령어를 이용했었다는 것을 기억할 것입니다. 피연산자가 필요하지 않은 iconst_1 명령어가 bipush 보다 효율적으로 동작하기 때문에 이곳에서는 iconst_1 명령어가 사용되었습니다. iconst_<i> 명령어는 총 7개로 -1에서 5까지의 값만 로드할 수 있기 때문에 앞선 코드에서는 10을 넣기 위해 bipush가 사용되었던 것입니다.
각 명령어에 대한 자세한 내용은 앞서 언급했던 위키피디아의 명령어 리스트를 보면 쉽게 찾아볼 수 있습니다.
여기까지 바이트코드에 대한 기본적인 내용을 알아보았습니다. 이제 어떤 코드의 동작방식이 궁금하다면 명령어 리스트를 참고해가며 직접 바이트코드를 분석해 볼 수 있을 것입니다. 좀 더 깊은 내용을 알고 싶다면 JVM 스팩을 살펴보는 것을 추천해 드립니다.




